Pandas速查
type
Post
date
Nov 5, 2021
summary
pandas 是基于NumPy的一种工具,pandas提供了大量能使我们快速便捷地处理数据的函数和方法。它是使Python成为强大而高效的数据分析环境的重要因素之一。
category
学习笔记
tags
pandas
速查
Python数据处理三板斧
password
URL
Property
Jun 20, 2025 01:47 AM
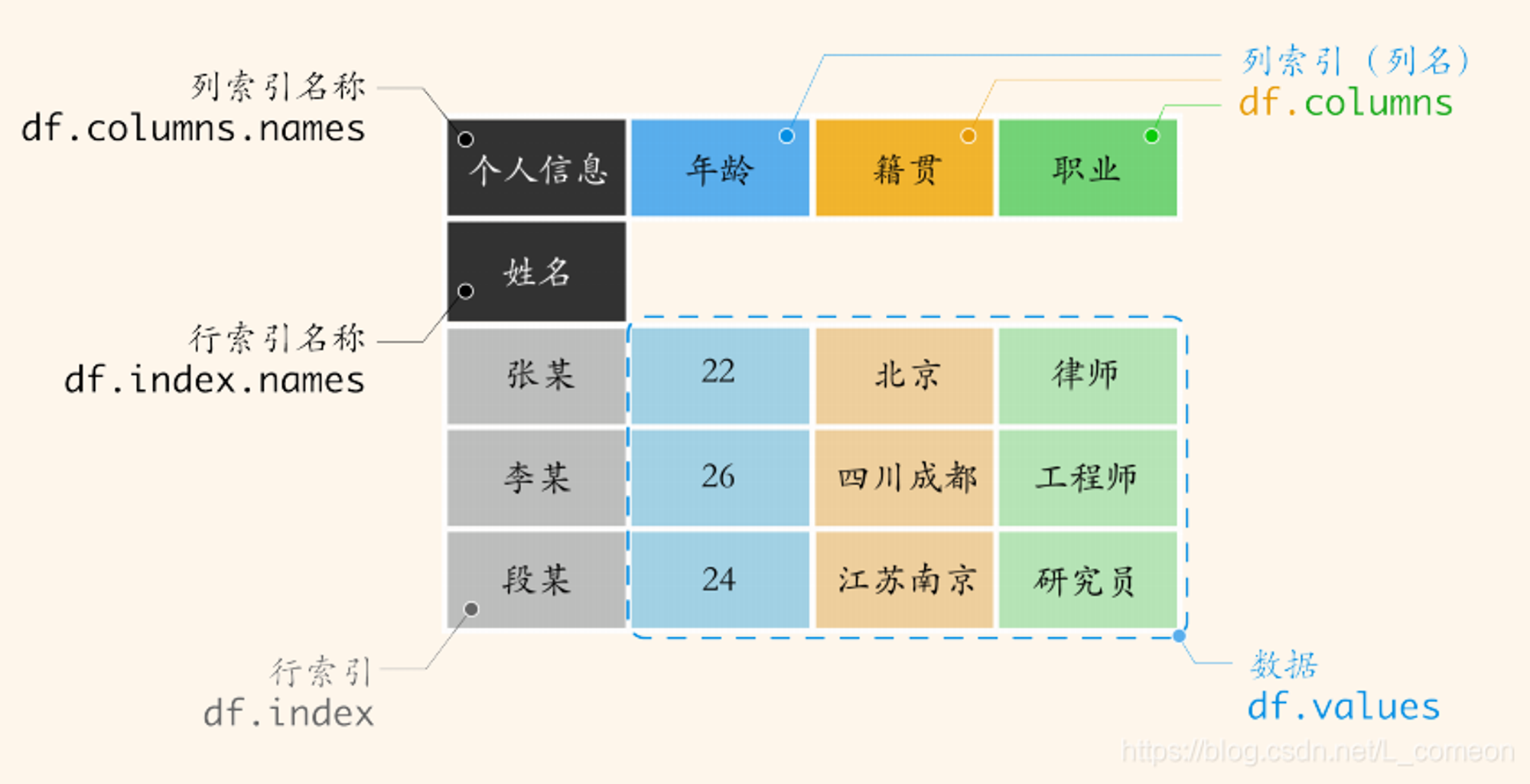
Pandas有两类数据类型:Series和DataFrame



数据读写
# 从文件中读取数据 pd.read_csv(filepath_or_buffer, sep=',',header) # header指定行数用来作为列名,数据开始行数。如果文件中没有列名,则默认为0,否则设置为None。如果明确设定header=0 就会替换掉原来存在列名。 # header参数可以是一个list例如:[0,1,3],这个list表示将文件中的这些行作为列标题(意味着每一列有多个标题),介于中间的行将被忽略掉 pd.read_table() # 从制表符分隔文件读取,如TSV pd.read_excel() pd.read_sql() pd.read_json() # 从数据写入文件 pd.to_csv(path_or_buf) pd.to_table() pd.to_excel() pd.to_sql() pd.to_json() pd.to_pickle() # 压缩文件
数据生成
pd.Series() # pd.DataFrame() # pd.DataFrame(columns=['A']) # 创建一个列名为A的空DataFrame a=[1,2,3,4]#列表a b=[5,6,7,8]#列表b c={"a" : a, "b" : b}#将列表a,b转换成字典 data=DataFrame(c)#将字典转换成为数据框 a=[[1,2,3,4],[5,6,7,8]]#包含两个不同的子列表[1,2,3,4]和[5,6,7,8] data=DataFrame(a)#这时候是以行为标准写入的size
查看数据
pd.set_option('display.max_columns', None) # 显示所有列 pd.set_option('display.max_rows',None) # 显示所有行 pd.set_option('display.max_colwidth', 200) # 设置每列的最大显示宽度 df = pd.read_csv() # 读取CSV文件 df.head() # 查看数据前几行,默认前五行,可手动输入数据如:df.head(100) df.shape # 查看数据形状,df.shape[0] -读取矩阵第一维度的长度(行的长度) df.info() # 样本数、数据类型和内存占用等信息 df.info(null_counts=True) # 查看数据信息,顺便统计空值 df.describe() # 统计数据:均值,最大值,最小值等 df.count() # 统计非空值 df.dtypes # 查看数据类型 df.isnull() # 判断值是否为空,返回布尔值 df.isnull().any(axis=0) # 判断行或列是否有缺失值 df.isnull().sum(axis=0) # 统计出行或列有多少个缺失值 df.index # 行索引(行号),返回的是一个对象 df.index.values # 查看行索引,返回的是一个一维数组具体的值 df.index.get_level_values(0) # 获取多重索引中第一层的索引值 df.index.get_level_values('index_name') # 获取多重索引中名称为index_name的索引值 df.index.is_unique # 索引是否唯一 df.index.map(str.upper) # 对索引调用映射关系map df = df.set_index() # 🚩将某列或某几列设置为行索引 df = df.reset_index() # 重置索引;不想保留原来的index,用参数 drop=True df.reindex(['a','b','c']) # 设置新索引为'a','b','c' ,若新索引名不在旧索引中,则用NaN填充该行;若旧索引不在新索引中,则删除整行。 df.index = ['a','b','c'] # 设置新索引(这里的新索引的数量必须和旧索引的数量一直,不然报错) df.columns # 列索引(列名) df.columns.values # 查看列索引 df.columns.get_level_values(0) # 获取多重索引中第一层的索引值 df.columns.get_level_values('index_name') # 获取多重索引中名称为index_name的索引值 df.columns = ['a','b','c'] # 设置新列名(这里的新列名的数量必须和旧列名的数量一直,不然报错) df.rename() # 🚩可以同时对index和columns进行修改 df.tail() # 查看数据后几行,默认后五行,可手动输入数据如:df.tail(100)
查询数据
# 获取所有数据,返回numpy.ndarray类型 df.values df['A'].values # 直接获取 df.clo1 # df['clo1'] # 得到series类型 df[['col1']] # 得到dataframe类型 df[['col1','clo2']] # # 只能获取某些行 df[:] df[0:3] df['index1':'index2'] # 官方推荐选择数据的方法为.at, .iat, .loc, .iloc # loc和at对行名和列名进行操作,iloc和iat对行位置和列位置进行操作 # 标签选择:loc和at # at不支持类型隐式转换,而loc是支持的;at的速度比loc要快 df.loc['index1'] df.loc['index1', 'col1'] df.at['index1', 'col1'] df.loc['index1':'index2'] df.loc['index1':'index2', 'col1':'col2'] df.loc['index1':'index2', ['col1','col2']] # 直接用loc进行赋值操作 df.loc[df['年收入']<=100000, '年收入层级'] = 'Low' # 将'年收入'小于等于10w的'年收入层级'赋值为'Low' # 位置选择:iloc和iat df.iloc[3] # 选择第n行数据,数据类型为Series df.iloc[1,2] # 选择具体元素,数据类型为具体的值 df.iat[1,2] # 选择具体元素 df.iloc[:, 0:2] # 选择所有行,某些列数据 df.iloc[3, 0:2] # 选择第n行,某几列数据,使用逗号间隔,按照左闭右开方式截取数据。 df.iloc[0:3, 0:2] # 选择某几行,某列数据 # 不包含某列选数 df.iloc[:, df.columns != 'col'] # 选择不包含col列的其他数据,这里也可以用loc方法 df.iloc[:, ~df.columns isin 'col'] # 选择不包含col列的其他数据,这里也可以用loc方法 df[df.columns.difference(['A', 'B'])] # 选择不包含A,B两列的其他数据 # 条件选择 df[df['col1']>1] # 根据某列值进行筛选 df[df>0] # 对整个dataframe进行筛选,不符合条件的值会被置为NaN df[df['col3'].isin([2,4])] # 得到col3列值在2和4里面的行 df[~df['col1'].isnull()] # 得到col1列值为非空的行 # 根据字段类型选择字段 df.select_dtypes(include='object') 'int64','float64' # 优雅的query(如果字段的值是字符串,需要再用一层引号把值引起来(中文字段名可以直接使用不影响)) df.query(expr,inplace = False,** kwargs ) # 使用布尔表达式查询数据;主要参数为expr,它是字符串表达式; # 在表达式中可以用@引用变量 p_name = 'Scouts' df.query('regiment==@p_name') # 如果表达式中使用到的字段名中包含空格,则需要将字段名用反引号``引起来 df.query('A < `C C`') # 表达式中多条件可以使用and、or、&、| df.query('A < B | A == 4') # 还可以直接使用index,可以使用in、not in,这里不能用双等号代替in df.query('index in (1,2,3)') df.query('readiness in (1,2) or regiment in ("Scouts") ') # ==和!=可以代替in和not in params=["Nighthawks","Scouts"] df.query('regiment==@params') # 这里@引用的变量不能是 series # 用bools判断布尔值(会新增一列bools,判断当前行是不是由布尔值组成) df.query('bools') df.query('not bools') # 用not、~可以表示取反 df.query('~bools') # 判断空值和非空 df.query('A.isnull()') df.query('A.notnull()') # 根据数据类型选择数据 df.select_dtypes(include=None, exclude=None) # 返回包含或排除某种数据类型之后的数据,两个参数至少提供一个 df.select_dtypes(include=['int64','float64']) # 多种类型用列表包裹 df.select_dtypes(include="number") # 选择数值型数据 # 可选类型有:number、object、datetime、timedelta、bool、float64、int64等
数据统计
import pandas as pd df.cumsum() # 累计 df.var() # 方差 df.std() # 🚩标准差(📢:pd中的std和np中的std默认计算结果是不一致的,详情见解析) df['A'].cov(df['B']) df.cov() # 协方差矩阵 df.corr() # 🚩相关性系数矩阵 df.rank() # 数据框排名 df['A'].value_counts() # 统计A列每个值的数量,从大到小排列(会忽略空值!!!) df['A'].value_counts(dropna=False) # 统计A列每个值的数量,从大到小排列(不忽略空值!!!) df['A'].value_counts(normalize=True, dropna=False) # 统计A列每个值的数量占比,从大到小排列,不忽略空值!!! df['A'].value_counts(1, dropna=False) # 统计A列每个值的数量占比,从大到小排列,不忽略空值!!! counts = df['A'].value_counts(dropna=False) # 计算每个值的数量,包括空值 percentages = df['A'].value_counts(normalize=True, dropna=False) # 计算每个值的占比,包括空值 result = pd.DataFrame({ 'Count': counts, 'Percentage': percentages }) # 创建一个 DataFrame 来显示数量和占比 df['A'].max() # 返回Dataframe列中的最大值 df['A'].min() # 返回Dataframe列中的最低值 de['A'].mode() # 众数,对字符串也能有用 df.median() # 返回Dataframe每列的中位数 df.quantile() # 🚩分位数计算 # 分组的函数的运算效率是根据需要分组的字段的值的多少来看的,值越多,越慢 df.groupby('A').apply(lambda x: x) # 查看groupby之后的结果 df.groupby('A').size() # 根据'A'列进行分组,对所有的列进行计数汇总(包含空值) df.groupby('A').count() # 根据'A'列进行分组,对所有的列进行计数汇总(不包含空值) df.groupby('A')['id'].count() # 根据'A'列进行分组,对['id']列进行计数汇总(不包含空值) df.groupby(['A','B'])['C'].mean() # 根据多个字段进行分组时,如果有字段值为空,则会报错,所以应该先填充 df.groupby('A')['B'].agg([len, np.sum, np.mean]) # 根据'A'列进行分组,对B列进行多种操作 df.groupby('A').agg({'B': np.sum, 'C': np.mean}) # 根据'A'列进行分组,对B、C列进行不同的操作 df.groupby('A')['B'].transform(np.mean) df['%'] = df['sales'] / df.groupby('state')['sales'].transform('sum') # 求state的每个组内的每个内容占该组的比例,参考 # agg和transform的区别是:agg返回一个聚合值,transform返回多个一样的聚合值(根据分组后的数据决定) # 分组后组内排序 df.groupby('B').apply(lambda x: x.sort_values('C', ascending=False)) # 先分组后排序 df.sort_values('C', ascending=False).groupby('B') # 先排序后分组 # 分组后 取每个组内的 不同列的 几条数据 做运算 def concat_func(x): # 根据ABC分组后 取每组内 D列的最后一行的值 减去 E列的第一行的值 return x.tail(1)['D'].values - x.head(1)['E'].values }) data_one.groupby(['A','B','C']).apply(concat_func) # 分组后将组内数据拼接(使用Series的 str.cat 方法) # 注意:Series的数据类型必须要为字符串,如果不是,可以使用 astype 进行转换 s = pd.Series(['a', 'b', np.nan, 'd']) s.str.cat(sep=' ') # 除了cat还有拆分str.split()、替换str.replace()、分列str.extract(r'')使用正则来实现分列 s = pd.Series(["A_Str_Series"]) s.str.replace("_", "") s.str.split("_") s = pd.Series(['a1', 'b2', 'c3']) s.str.extract(r'([ab])(\d)') s.str.extract(r'([ab])?(\d)') s.str.extract(r'(?P<letter>[ab])(?P<digit>\d)')
处理方法
df.duplicated(subset=None, keep=False) # 找出重复行,找出指定字段重复的行,subset指定的字段列表; # keep:False —— 所有重复项都为True;keep:first —— 第一次出现的值设置为False,其他所有值设置为True;keep:last —— 最后一次出现的值设置为False,其他所有值设置为True; df.drop_duplicates() # 🚩删除重复行 df['col'].unique() # 单个series去重复 df['col'] = df['col'].astype('int') # 设置数据类型从 df.rename(columns={'col': 'col1'}) # 重置列名 df['col'].str.replace('\', '-') # 字符替换 df['col'].str.split('-') # 切割 pd.pivot_table(df,index=[]) # 🚩数据透视表 pd.crosstab() # 📌数据交叉表(详解待整理) df['columns'].unique() # 以数组形式返回列的所有唯一值 df['columns'].nunique() # 返回的是唯一值的个数 df.apply() # 🚩后面可接内置函数、lambda函数、自定义函数,数据量太大时使用swifter包提速 data['A'] = data['A'].apply(lambda x: x[6:10]) # 对A列每个元素进行处理 df.get_dummies(df, columns=['A'],drop_first=True) # 🚩对A列进行one-hot编码 pd.cut(df['A'],[0, 5, 10], ['A','B','C']) # 🚩平均分箱 pd.qcut(df['A'],4) # 按分位数分箱 df.sample(frac=0.5) # 🚩从 df/Series 中随机抽取样本 pd.MultiIndex # 🚩设置多级表头 df.insert(loc=2,column='org_name',value=values) # 在指定位置插入列,loc是插入的位置,values可以是int、list、series # 无穷值处理 df.replace([np.inf,-np.inf,np.nan,],0,inplace=True) # 替换正负inf,NAN为0,加inplace参数 df['Col'][np.isinf(df['Col'])] = -1 # 替换某一列的无穷值为-1 # 缺失值处理 df.isnull() # 判断值是否为空,返回布尔值 df.isnull().any(axis=0) # 判断行或列是否有缺失值 df.isnull().sum(axis=0) # 统计出行或列有多少个缺失值 df.fillna(0) # 空值填充 df.dropna() # 🚩删除空值所在行 np.isnan(df) # 判断数据内是否有空值 np.isinf(df) # 判断数据内是否有无穷数据 df['col'].fillna(df['col'].mean()) # 用均值填充空值 df[df['TotalCharges'] == ' '] # 有的数据可能会采用'Null'、'NaN'、' ' 等字符(串)表示缺失,需要额外注意 # 🚩合并数据 pd.merge(data1,data2,how='inner',on='id') data1.join(data2, how='right') pd.concat([data1,data2],axis=1,join='inner') data1.append(data2) # 纵向 # 排序 df.sort_index(axis=0, ascending=True, inplace=False) # 按标签排序 # axis=0 或 axis=‘index’ 按行号排序;axis=1 或 axis=‘columns’ 按列明排序; # ascending=True 升序排列;ascending=False 降序排列; # inplace=True/False 是否用排序后的数据框替换现有的数据框; df.sort_values(by='columns_name', axis=0, ascending=True, inplace=False) # 按值排序 # by后面可以跟一个列名,也可以跟多个列名组成的列表 df.rank() # 🚩返回对指定数据的排名名次,可以和groupby联合使用,获得分组后的组内排名 # 数据重塑 df.pivot(index=None, columns=None, values=None) # 🚩透视表 df.stack(level=-1, dropna=True) # 将列数据堆叠到行,level指定堆叠的目标位置,-1 表示最后一层(最内层);返回一个多级索引的df/series; df.unstack(level=-1, fill_value=None) # 将行数据旋转到列,level指定解除堆叠的索引位置,-1 表示最后一层(最内层);(pandas行转列、列转行、以及一行生成多行) pd.melt(df,id_vars=["水果", "姓名"]) # id_vars:指定要保留为标识符的列名,并默认将其他所有列名当作新增列的值 df.explode('A') # A 列的某一行有多个值时,对其进行炸裂变成多行,(需要先将多个值放到列表中:df = df["A"].str.split(",")) df.idxmin(axis = 0) # 获取每列最小值对应的索引 df.idxmin(axis = 1) # 获取每行最小值对应的列名
其他方法
# 将DataFrame转换成可迭代对象 df.iterrows() # 返回一个迭代器,每次迭代生成一个包含两个元素的元组,分别是行索引和该行的数据(series)。 df.iteritems() # 将DataFrame迭代成(列名,series) df.itertuples() # 将DataFrame迭代成元组
常用的组合方法
dupNum = df.shape[0] - df.drop_duplicates().shape[0] # 整个数据集中重复样本的数量
常用函数详解(有🚩的函数才有详解)
1、to_numeric函数
作用:将特征转换为数字类型。
形式:
pd.to_numeric(arg, errors='raise', downcast=None)
参数:
arg:scalar, list, tuple, 1-d array, 或 Series errors:{‘ignore’, ‘raise’, ‘coerce’}, 默认为 ‘raise’ - 如果为‘raise’,则无效的解析将引发异常。 - 如果为‘coerce’,则将无效解析设置为NaN。 - 如果为‘ignore’,则无效的解析忽略。 downcast:{‘integer’, ‘signed’, ‘unsigned’, ‘float’}, 默认为 None; 如果不是None,并且数据已成功转换为数字dtype(或者数据是从数字开始的),则根据以下规则将结果数据转换为可能的最小数字dtype: - ‘integer’或‘signed’:最小有符号整数类型(最小值:np.int8) - ‘unsigned’:最小的无符号整数dtype(最小值:np.uint8) - ‘float’:最小浮点dtype(最小值:np.float32)
实例:(使用to_numeric压缩数据)
data = pd.read_csv("features.csv") print(data.info()) # 数据压缩 fcols = data.select_dtypes('float').columns icols = data.select_dtypes('integer').columns data[fcols] = data[fcols].apply(pd.to_numeric, downcast='float') data[icols] = data[icols].apply(pd.to_numeric, downcast='integer') data.info()
2、drop_duplicates函数
作用:对数据进行去重
形式:
pd.drop_duplicates(subset=['A','B'],keep='first',inplace=True)
参数:
subset: 输入要进行去重的列名,默认为None,表示所有列 keep: 可选参数有三个:‘first’、 ‘last’、 False, 默认值 ‘first’。其中, - first表示: 保留第一次出现的重复行,删除后面的重复行。 - last表示: 删除重复项,保留最后一次出现。 - False表示: 删除所有重复项。 inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。
3、map,apply,applymap函数
- map()的功能是将一个自定义函数作用于Series对象的每个元素。map方法都是把对应的数据逐个当作参数传函数
- apply()函数的功能是将一个自定义函数作用于DataFrame的(多)行或者(多)列;也可以作用于Series对象
- 作用于Series对象时,apply相比map能够传入功能更为复杂的函数
def func(x,y): return x + y data3 = data2['A'].apply(func,y=8)
def BMI(series): weight = series["weight"] height = series["height"]/100 BMI = weight/height**2 return BMI data["BMI"] = data.apply(BMI,axis=1)
如果传给apply的函数能够接受其他参数或关键字,则可以将这些内容放在函数名后面一井传入;
- applymap()函数的功能是将自定义函数作用于DataFrame的所有元素
使用经验
返回多列怎么接收
使用场景:调用函数后可能会得到多个值,这时我们用多个列名取直接接收会报错
报错原因:调用函数时,即使函数return后面是多个值,但是最终map、apply会将其整合为一个set类型的数据
解决方法:
1、在apply后再加一个.apply(pd.Series)
注:如果运用函数的字段数比函数输出的字段数少,则会报错,这时可以随便加一个凑数字段
def split_content(x): x_split = x.split(' ') return x_split[13],x_split[14],x_split[15],x_split[16],x_split[17],x_split[18] data_one[['A','B','C','D','E','F']] = data_one['op_content'].apply(split_content).apply(pd.Series)
2、在apply调用的函数内部使用pd.Series;
def concat_func(x): return pd.Series({ 'op_order_code': ','.join(x['module_level1_code'].unique()), 'op_order_name': ','.join(x['module_level1_name'].unique()), 'op_duration': int(x.tail(1)['op_end_time_unix'].values - x.head(1)['op_time_unix'].values), 'op_obj_sstv_time' : x['op_obj_sstv'].sum(), 'op_obj_time' : x['module_level3_name'].count(), 'op_result_fail_time' : x['op_result'].sum(), 'jinku_auth_time' : x['jinku_auth_id'].count(), 'batch_op_time' : x['is_batch_op'].sum(), 'user_ahthorized_time' : x['is_user_ahthorized'].count() }) data_one.groupby(['acct_4a_name','sub_account_name','op_time_class']).apply(concat_func)
- 进一步优化:将 传入的DataFrame转换为numpy.ndarray类型,使用 numpy 的方法进行运算,效率会有大幅提升
def polynerization_ fun (x): x_values = x.values # print (x_values) return pd Series({ 'ALL_ARFT' : np.nean(x_values[:,2]), 'ALL_FLOW' : np.nean(x_values [:, 3]), 'ALL_CALL_DUR_M': np.sum(x_ values [:, 4]), 'ALL_CALL_CNT' : np.sum(x_values [:,5]), 'INITIATIVE_PERCENT': x_values[0,4] / (np.sum(x_values[:, 4])+0.001) })
map内的匿名函数中使用 if ... in 会报错
使用场景:在map中使用匿名函数,判断x是否在一个列表中,直接写 lambda x: x if x in list_ 则会报错;
解决方法:用 lambda x: x in list_ 生成一个布尔值组成的列,再用这一列进行过滤
数据量太大时可以使用swifter包为apply提速
!pip install swifter pip install -U "swifter[groupby]" # 适用grouby+apply import swifter df['new'] = df['new'].swifter.apply(func,axis=1)
4、pivot_table透视表
作用:对数据动态排布并且分类汇总
形式:
pd.pivot_table(data, values=None, index=None, columns=None,aggfunc=‘mean’, margins=False)
参数:
data:【必须】需要操作数据 DataFrame values:要进行计算操作的列名(也就是指标,要统计的指标) 一个列名或列名组成的列表,不给代表对所有列操作 index:【必须】分组后作为列索引的列名(根据这个来分组) 一个列名或列名组成的列表 columns:分组后作为行索引的列名(将这个参数的枚举值作为透视表的列名称) 一个列名或列名组成的列表 aggfunc:指定对values参数所给的列做什么计算操作(计算的函数:np.sum,np.mean),可以是字典(分别为不同的列指定不同的计算操作),默认为mean(计算均值) margins:是否进行行汇总和列汇总
参考:
4.1、衍生pivot()函数
功能:对数据进行重构
形式:
df.pivot(index=None, columns=None, values=None)
参数:
参数: index : 选择已有的列名称,用来当作新数据index。 如果没有,则使用现有的索引。 columns : 选择已有的列名称,将该列的数据枚举值当作新数据的列明。 values : 选择已有的列名称,将该列的数据当作新数据的value。如果未指定,则将使用所有剩余列,结果将具有分层索引列 返回: DataFrame
示例:

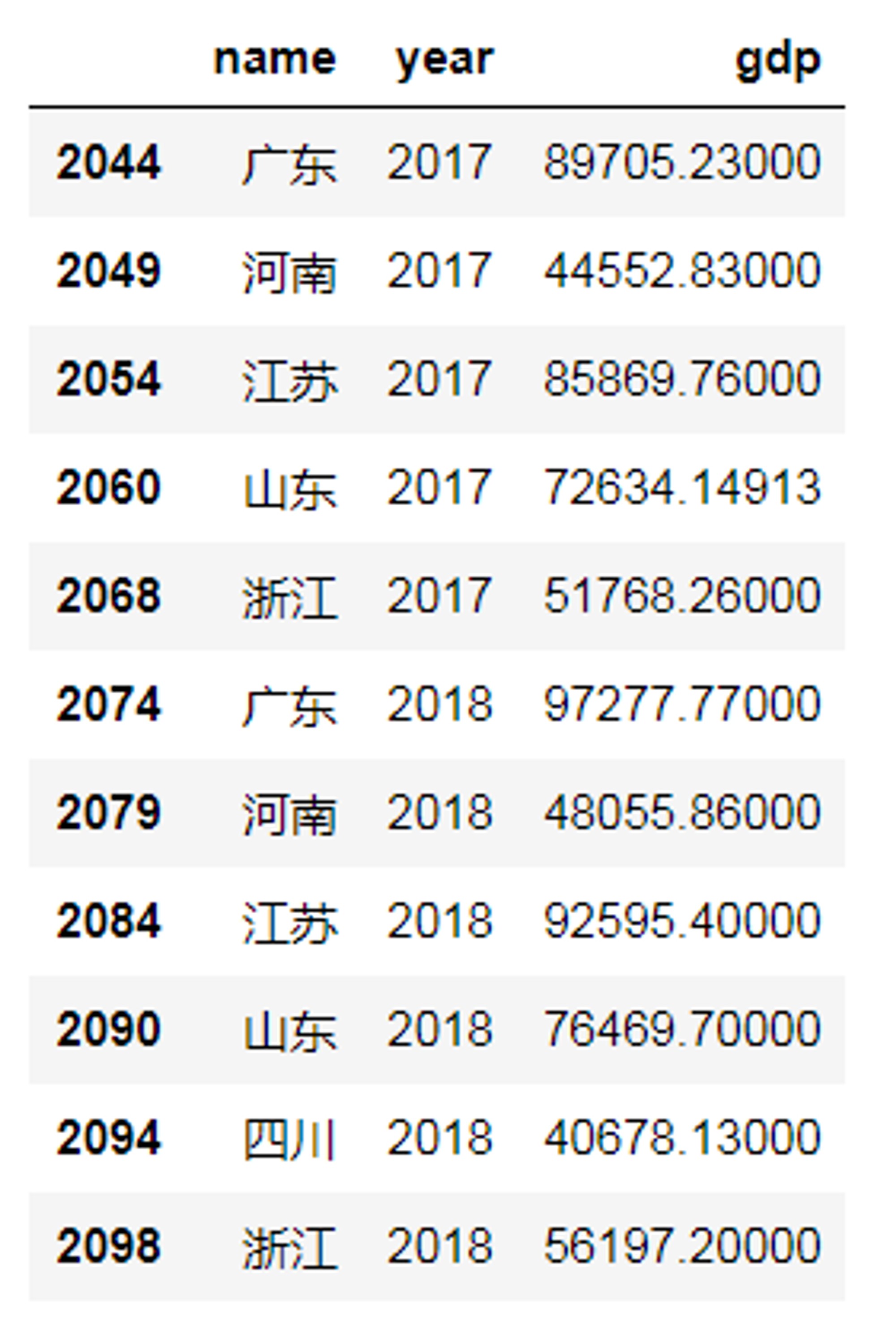

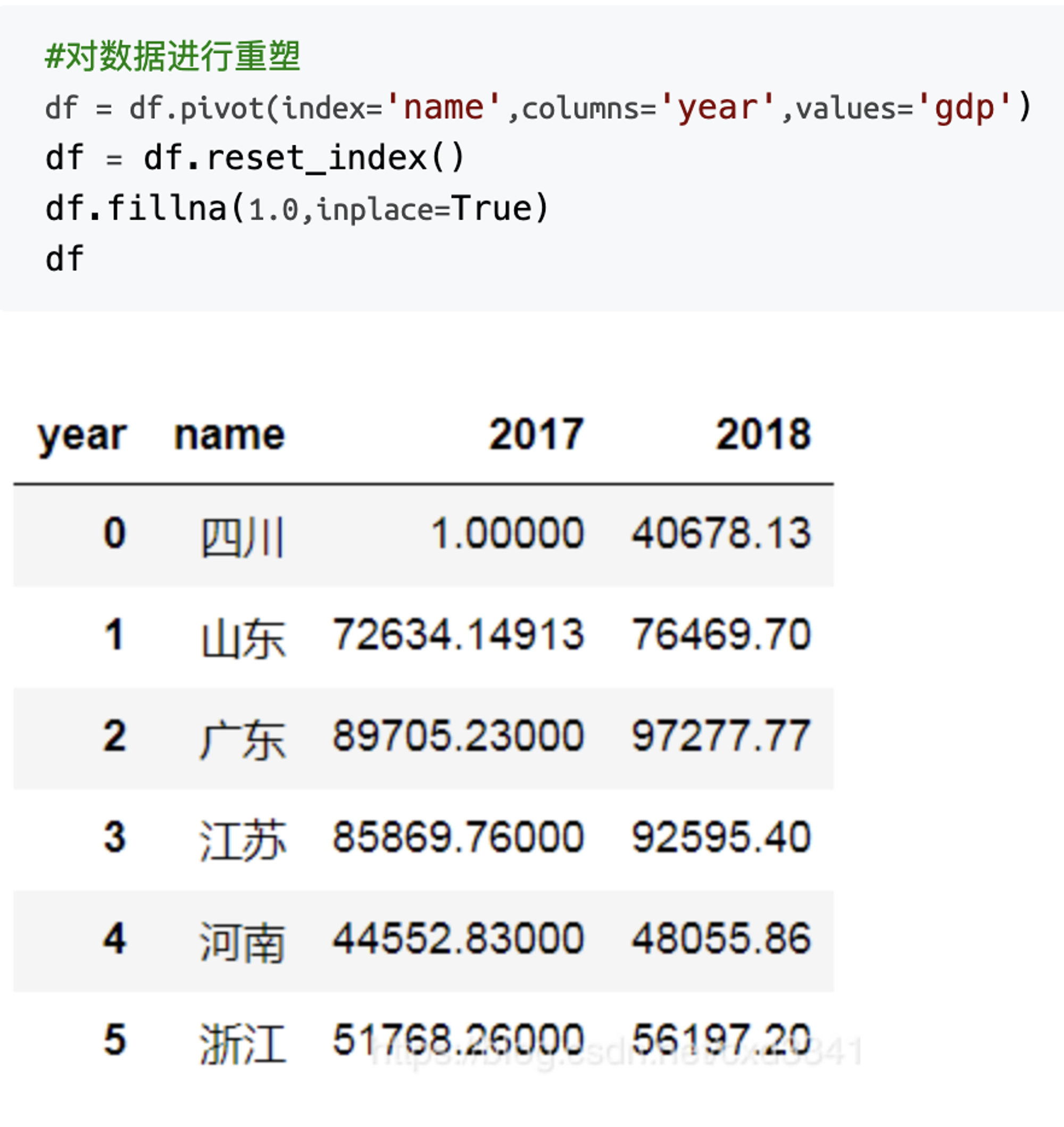
5、get_dummies独热编码
作用:实现独热编码
形式:
pandas.get_dummies(data, prefix=None, prefix_sep=’_’, dummy_na=False, columns=None, sparse=False, drop_first=False)[source]
参数:
data : array-like, Series, or DataFrame 输入的数据 prefix : string, list of strings, or dict of strings, default None。get_dummies转换后,列名的前缀 prefix_sep : string, default ‘_’。连接前缀和列名的链接符号。 columns : list-like, default None。指定需要实现类别转换的列名 dummy_na : bool, default False,增加一列表示空缺值,如果False就忽略空缺值 drop_first : bool, default False,获得k中的k-1个类别值,去除第一个。 若DataFrame中有数值型特征(columns),数值型column则保留原始值
6、concat,merge,join和append的区别
6.1、concat
形式:
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
参数:
objs:【必须】series,dataframe或者是这两种类型构成的序列lsit axis:【必须】指明连接的轴向, {0/’index’(行), 1/’columns’(列)},默认为0 join:【必须】指明连接方式 , {‘inner’(交集), ‘outer(并集)’},默认为outer join_axes:自定义的索引。指定索引进行拼接, 而非默认join =’ inner’或’outer’方式拼接 ignore_index=True:重建索引 keys:连接后标明数据来自哪一块;创建层次化索引。可以是任意值的列表或数组、元组数组、数组列表(如果将levels设置成多级数组的话)
说明:
当join='outer'时:(数据连接之后行名和列名都有可能重复) 1、axis=0时,类似于SQL的union all,将两组数据上下拼接;如果两组数据的列相同,则直接拼接;如果两组数据的列不完全同,则取两组数据的列的并集去重,没有的数据填NaN 2、axis=1时,类似于SQL的out join,将两组数据左右拼接;如果两组数据的行相同,则直接拼接;如果两组数据的行不完全同,则取两组数据的行的并集去重,没有的数据填NaN 当join='inner'时: 1、axis=0时,取两组数据都有的列,然后上下拼接 2、axis=1时,取两组数据都有的行,然后左右拼接 concat可以对多个数组同时进行拼接
6.2、merge
形式:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
参数:
left和right:两个不同的DataFrame或Series how:连接方式,有inner、left、right、outer,默认为inner on:用于连接的列索引名称,必须同时存在于左、右两个DataFrame中,默认是以两个DataFrame列名的交集作为连接键,若要实现多键连接,‘on’参数后传入多键列表即可 left_on:左侧DataFrame中用于连接键的列名,这个参数在左右列名不同,含义相同时使用(如果两个表的连接列名相同则用on); right_on:右侧DataFrame中用于连接键的列名, left_index:使用左侧DataFrame中的行索引作为连接键(但是这种情况下最好用JOIN) right_index:使用右侧DataFrame中的行索引作为连接键(但是这种情况下最好用JOIN) sort:默认为False,将合并的数据进行排序,设置为False可以提高性能 suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(’_x’, ‘_y’) copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能 indicator:显示合并数据中数据的来源情况
说明:
merge的主要功能是将两个(只能是两个)DatFrame左右连接,类似SQL中的连表(join)合并表的列数等于两个原数据表的列数之和减去连接键的数量。 merge默认会丢弃原来的索引,重新生成索引;用index连接的话,索引不变 merge的原理和SQL的连表操作很类似,值得注意的是如果是多条件链接,则在on后面传入多条件组成的列表即可(多条件左右链接只能用marge实现)
6.3、join
形式:
DataFrame.join(other, on=None, how='left', lsuffix=' ', rsuffix=' ', sort=False)
参数:
参数的意义与merge方法基本相同,只是join方法默认为左外连接how=’left’
说明:
left.join(right,on=l_col) 用left表去join right表,基本思想是用left表的某一列l_col去连接right表的index,索引能引申出以下用法: 用法一:left.join(right) # 直接用两表的index进行连接,若两表中有相同的列名,需要指定参数lsuffix='', rsuffix='' 用法二:left.join(right.set_index('col_r'),on='col_l') # 将右表中的连接字段先设置为右表的索引,再和左表连接,这里要指定左表的连接字段
join 主要是用于基于索引的合并,而 merge 是基于列的合并6.4、append(As of pandas 2.0, append was removed!!!)
append形式:
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
参数:
other:DataFrame,series,dict,list这样的数据结构 ignore_index:【默认False】,是否重置合并后的数据的索引 verify_integrity :默认False,如果为True当创建相同的index时会抛出ValueError的异常 sort: boolean,默认None
说明:
append是concat的简略形式,只不过只能在axis=0上进行合并,如果添加的列名不在dataframe对象中,将会被当作新的列进行添加
7、drop和delete函数
delete函数删除指定列,改变DataFrame的存储空间
drop函数在丢弃指定项时返回的是视图,并不会改变DataFrame本身的存储空间
7.1 drop
作用:
Drop specified labels from rows or columns.
形式:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
参数:
labels: single label or list-like Index or column labels to drop. axis: {0 or ‘index’, 1 or ‘columns’}, default 0 Whether to drop labels from the index (0 or ‘index’) or columns (1 or ‘columns’). index: single label or list-like Alternative to specifying axis (labels, axis=0 is equivalent to index=labels). columns: single label or list-like Alternative to specifying axis (labels, axis=1 is equivalent to columns=labels). level: int or level name, optional For MultiIndex, level from which the labels will be removed. inplace: bool, default False If False, return a copy. Otherwise, do operation inplace and return None. errors: {‘ignore’, ‘raise’}, default ‘raise’ If ‘ignore’, suppress error and only existing labels are dropped.
推荐阅读
8、corr相关系数
作用:
Compute correlation with other Series, excluding missing values.
形式:
Series.corr(other, method='pearson', min_periods=None)
参数:
other: Series Series with which to compute the correlation. method: {‘pearson’, ‘kendall’, ‘spearman’} or callable Method used to compute correlation: pearson : Standard correlation coefficient kendall : Kendall Tau correlation coefficient spearman : Spearman rank correlation callable: Callable with input two 1d ndarrays and returning a float. New in version 0.24.0: Note that the returned matrix from corr will have 1 along the diagonals and will be symmetric regardless of the callable’s behavior. min_periodsint, optional Minimum number of observations needed to have a valid result.
9、set_index()
作用:将现有的某列或多列设置为索引
形式:
df.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
参数:
keys:label or array-like or list of labels/arrays,这个是需要设置为索引的列名,可以是单个列名,或者是多个列名组成的列表 drop:bool, default True,是否删除要用作新索引的列,默认删除 append:bool, default False,是添加新索引,还是取代新索引(是否保留原来的index),默认取代 inplace:bool, default False,是否要覆盖原数据集 verify_integrity:bool, default False,检查新索引是否重复。否则,将检查推迟到必要时进行。设置为False将改善此方法的性能
10、rename()
作用:修改行名和列名的相关
形式:
df.rename(mapper = None,index = None,columns = None,axis = None,copy = True,inplace = False,level = None )
参数:
mapper,index,columns:三个参数可以任选其一使用;如果这里使用mapper则后面用axis选择作用方向;这三个参数可以是映射字典,也可以是一个函数 axis:int或str,与mapper配合使用。可以是轴名称(‘index’,‘columns’)或数字(0,1)。【默认为’index’】。 copy:boolean,【默认为True】,是否复制基础数据。 inplace:布尔值,【默认为False】,是否返回新的DataFrame。如果为True,则忽略复制值。
用例:
df.rename({0:111}) # 第一行的索引由0变成111 df.rename(lambda x: x+11) # 索引都加11 df.rename(lambda x: x+11, axis=1) # 列名都加11 df.rename(index=str.lower, columns=str.upper) # 索引小写,列名大写
11、quantile()
作用:计算分位数
形式:
df.quantile(q=0.5, axis=0, numeric_only=True, interpolation=’linear’)
参数:
q : 数字或者是类列表,范围只能在0-1之间,默认是0.5,即中位数-第2四分位数 axis :计算方向,可以是 {0, 1, ‘index’, ‘columns’}中之一,默认为 0 interpolation(插值方法):可以是 {‘linear’, ‘lower’, ‘higher’, ‘midpoint’, ‘nearest’}之一,默认是linear。 当计算出来的分位数不在数组中时, linear表示取计算出来的值作为分位数 lower表示计算值向下取一位作为分位数 higher表示计算值向上取一位作为分位数 midpoint表示计算值上下两个值的平均值 nearest未知
注意:
在使用quantile()函数前需要先将数据排好序
12、MultiIndex()
MultiIndex方法可用于列名和索引
pd.MultiIndex.from_arrays(arrays,sortorder,names) # 将数组转变为多级索引 # arrays:数组组成的列表或序列 # sortorder:排序级别,一般不使用 # names:每级索引的名字 >>> arrays = [[1, 1, 2, 2], ['red', 'blue', 'red', 'blue']] >>> df.columns / df.index = pd.MultiIndex.from_arrays(arrays, names=('number', 'color')) MultiIndex([(1, 'red'),(1, 'blue'),(2, 'red'),(2, 'blue')],names=['number', 'color']) pd.MultiIndex.from_tuples(tuples,sortorder,names) # 将元组转化为多级索引 # tuples:元组组成的列表或序列 >>> tuples = [(1, 'red'), (1, 'blue'),(2, 'red'), (2, 'blue')] >>> df.columns/df.index = pd.MultiIndex.from_tuples(tuples, names=('number', 'color')) MultiIndex([(1, 'red'),(1, 'blue'),(2, 'red'),(2, 'blue')],names=['number', 'color']) pd.MultiIndex.from_product(iterables,sortorder,names) # 将多个项目的笛卡尔积转换为多级索引 # iterables:可迭代对象组成的列表或序列 >>> numbers = [0, 1, 2] >>> colors = ['green', 'purple'] >>> df.columns/df.index = pd.MultiIndex.from_product([numbers, colors],names=['number', 'color']) MultiIndex([(0, 'green'),(0, 'purple'),(1, 'green'),(1, 'purple'),(2, 'green'),(2, 'purple')],names=['number','color']) pd.MultiIndex.from_frame(df,sortorder,names) # 将一个Dataframe转换为多级索引 >>> df = pd.DataFrame([['HI', 'Temp'], ['HI', 'Precip'],['NJ', 'Temp'], ['NJ', 'Precip']],columns=['a', 'b']) >>> df.columns/df.index = pd.MultiIndex.from_frame(df) # 如果不设置names参数,那么会直接使用df的列名作为names MultiIndex([('HI', 'Temp'),('HI', 'Precip'),('NJ', 'Temp'),('NJ', 'Precip')],names=['a', 'b'])
13、df.dropna()
删除空值所在的行/列
df.dropna(axis, how, thresh, subset, inplace)
参数详解:
参数 | 值 | 描述 |
axis | 0,1,'index','columns' | 可选, 默认值 0。0 和 'index' 删除有空值的行,1 和 'columns' 删除有空值的列 |
how | 'all', 'any' | 可选, 默认值 'any'。any指行/列有任意空值就删除,all表示行或列都为空值才删除 |
thresh | Number | 可选, 指定允许的非空值数目(当前行或列有空值,但是非空值的数量大于等于指定的tresh,则保留该行或列) |
subset | List | 可选, 指定行名或列名查找空值,必须以列表的形式(多个值是或的关系) |
inplace | TrueFalse | 可选, 默认值为 False。如果为 True:在当前 DataFrame 上执行删除操作。如果为 False:返回执行删除操作的副本 |
14、df.std()
原因在于默认情况下,
numpy计算的为总体标准偏差,ddof=0;一般在拥有所有数据的情况下,计算所有数据的标准差时使用,即最终除以n,而非n-1;
pandas计算的为样本标准偏差,ddof=1;一般在只有部分数据,但需要求得总体的标准差时使用,当只有部分数据时,根据统计规律,除以n时计算的标准差往往偏小,因此需要除以n-1,即n-ddof;
实际使用时需要注意,并且根据数据情况选择合适的函数,在数据量较大时,推荐使用numpy进行计算。
运行速度比较:
s1 = pd.Series([1,2,3,4,5]) #速度由快至慢 np.std(s1.values) > s1.std(ddof=0) > np.std(s1)
15、df.rank()
作用:以Series或者DataFrame的类型返回数据的排名(哪个类型调用返回哪个类型)
形式:
df.rank(axis=0,method='average',numeric_only=None,na_option='keep',ascending=True,pct=False)
参数:
axis:默认值0;设置沿着哪个轴计算排名(0列、1行) method:取值可以为'average','first','min', 'max','dense' 现有一组数据:[10,2,5,5,8] 按升序排名次,不同的方式如下: - 顺序排名: - first:[5,1,2,3,4] # 如果有相同的值,则按照出现的先后顺序排序; - 跳跃排名: - average:[5,1,2.5,2.5,4] # 如果有相同的值,将相同值的first排序名次求均值,代替所有相同值的名次,之后值的排序要进行名次跳跃 - min:[5,1,2,2,4] # 如果有相同的值,将相同值的first排序名次中的最小值,代替所有相同值的名次,之后值的排序要进行名次跳跃 - max:[5,1,3,3,4] # 如果有相同的值,将相同值的first排序名次中的最大值,代替所有相同值的名次,之后值的排序要进行名次跳跃 - 密集排名: - dense:[4,1,2,2,3] # 如果有相同的值,用一个名词给所有相同值排名,之后值的排序不跳跃 numeric_only:默认值None;是否仅仅计算数字型的columns,布尔值 na_option:默认值keep;NaN值是否参与排序及如何排序(‘keep’,‘top',’bottom') - keep:空值不参与排序 - top:空值为最小值 - bottom:空值为最大值 ascending:默认值True;设定升序排还是降序排,降序为False pct:默认值False;是否以排名的百分比显示排名(所有排名与最大排名的百分比)
技巧:可以和 groupby 组合使用,获取分组后的组内排序名次
16、pd.cut() & pd.qcut()
16.1、pd.cut() :按照数值或指定段进行分割
形式
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise', ordered=True)
参数
x:被切分的类数组(array-like)数据,必须是1维的(不能用DataFrame); bins:bins是被切割后的区间(或者叫“桶”、“箱”、“面元”),有3中形式:一个int型的标量、标量序列(数组)或者pandas.IntervalIndex 。 当bins为一个int型的标量时,代表将x平分成bins份。x的范围在每侧扩展0.1%,以包括x的最大值和最小值。 当bins为一个标量序列时,标量序列定义了被分割后每一个bin的区间边缘,此时x没有扩展。 当bins为pandas.IntervalIndex时,定义要使用的精确区间。 right:bool型参数,默认为True,表示是否包含区间右部。比如如果bins=[1,2,3],right=True,则区间为(1,2],(2,3];right=False,则区间为(1,2),(2,3)。 labels:给分割后的bins打标签,比如把年龄x分割成年龄段bins后,可以给年龄段打上诸如青年、中年的标签。labels的长度必须和划分后的区间长度相等,比如bins=[1,2,3],划分后有2个区间(1,2],(2,3],则labels的长度必须为2。如果指定labels=False,则返回x中的数据在第几个bin中(从0开始)。 retbins:bool型的参数,表示是否将分割后的bins返回,当bins为一个int型的标量时比较有用,这样可以得到划分后的区间,默认为False。 precision:保留区间小数点的位数,默认为3. include_lowest:bool型的参数,表示区间的左边是开还是闭的,默认为false,也就是不包含区间左部(闭)。 duplicates:是否允许重复区间。有两种选择:raise:不允许,drop:允许。
实例
import pandas as pd import numpy as np pd.cut(np.array([1, 7, 5, 4, 6, 3]), 3, labels=['第一段','第二段','第三段'], retbins=True) """ (['第一段', '第三段', '第二段', '第二段', '第三段', '第一段'] Categories (3, object): ['第一段' < '第二段' < '第三段'], array([0.994, 3. , 5. , 7. ])) """ pd.cut(np.array([1, 7, 5, 4, 6, 3]), [0,3,5,8], labels=['第一段','第二段','第三段'], retbins=True) """ (['第一段', '第三段', '第二段', '第二段', '第三段', '第一段'] Categories (3, object): ['第一段' < '第二段' < '第三段'], array([0, 3, 5, 8])) """ # 自定义分割区间 bins = pd.IntervalIndex.from_tuples([(0, 1), (2, 3), (4, 5)]) pd.cut([0, 0.5, 1.5, 2.5, 4.5], bins) [NaN, (0.0, 1.0], NaN, (2.0, 3.0], (4.0, 5.0]] Categories (3, interval[int64, right]): [(0, 1] < (2, 3] < (4, 5]]
16.2、pd.qcut() :按照分位数进行分割(每个分段内的数据量相同)
pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates='raise') # q,整数或分位数组成的数组 # 其余参数与cut相同
17、sample
作用:对 DataFrame 随机抽样
形式:
df.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None) Series.sample(n=None, frac=None, replace=False, weights=None, random_state=None)
参数:
n:表示要抽取的样本数量。如果未指定,则默认为1。如果指定了frac参数,则n将被忽略。 frac:表示要抽取的样本比例。取值范围为0到1之间。如果未指定n和frac参数,则默认为1(返回整个数据集)。 replace:表示是否允许重复抽样。如果设置为True,则允许重复抽样,即抽取的样本可能包含重复的元素;如果设置为False,则不允许重复抽样,默认为False。 weights:表示每个样本的权重。它可以是一个具有与数据集相同长度的列表或数组,用于指定每个样本的抽取概率。默认情况下,所有样本的权重相等。当给定一个列名时,按照某列的值计算权重取值。 random_state:表示随机数生成器的种子,用于控制抽样的随机性。通过指定相同的种子,可以确保每次运行时得到相同的抽样结果。 axis:仅适用于DataFrame对象,用于指定在哪个轴上进行抽样。默认为None,表示在行方向上进行抽样。
返回值:
- 如果抽样结果包含多个元素,则返回一个新的
DataFrame或Series对象,其中包含抽取的样本。
- 如果抽样结果只包含一个元素,则返回该元素的值。
3西格玛准则代码实现
import pandas as pd # 正态分布 # 3sigma准则 ---> # mean() - 3* std() ---下限 # mean() + 3* std() ---上限 # 自实现3sigma 原则 def three_sigma(ser): """ 自实现3sigma 原则 :param ser: 数据 :return: 处理完成的数据 """ bool_id = ((ser.mean() - 3 * ser.std()) <= ser) & (ser <= (ser.mean() + 3 * ser.std())) # bool数组索引 # ser[bool_id] return ser.index[bool_id] #使用detail 验证 deatil = pd.read_excel("./meal_order_detail.xlsx") print(deatil.shape) # 调用3sigma原则,进行异常值过滤 index_name_list = three_sigma(deatil['amounts']) deatil = deatil.loc[index_name_list,:] print(deatil.shape) #percentile() 计算分位数 # np.percentile() ql-1.5iqr qu + 1.5iqr
使用场景经验
判断某一列中的值在不在另一个序列中:使用map函数来实现
df[df['acct_4a_name'].map(lambda x: x in ['lizhimei2','ningliliang1'])]
在多种数据类型中选择数值类型的数据并做判断
df[df._get_numeric_data() < 0] = np.nan df[df<0]=np.nan # df 中全是数值时可以直接判断